
Achieving a stable Cloud Network without hitting Native Routing Limitations (ARS)
Table of Contents
Your cloud project, the beginning
You deployed your highly secure & encrypted Hub & Spoke model in Azure ( with Aviatrix), scaled up the environment and expanded into additional regions.
Next you want to migrate your workloads from OnPremise and empty your datacenters (does Cloud first sound known to you?)
You require a link with low latency for your sensitive apps (SAP, Databases) and good throughput/performance so you choose an Express Route circuit and deploy an Azure Route Server (ARS) to handle the routing information exchange between the 2 worlds.
Everything comes up seamlessly and by this time your design should look similar to this:
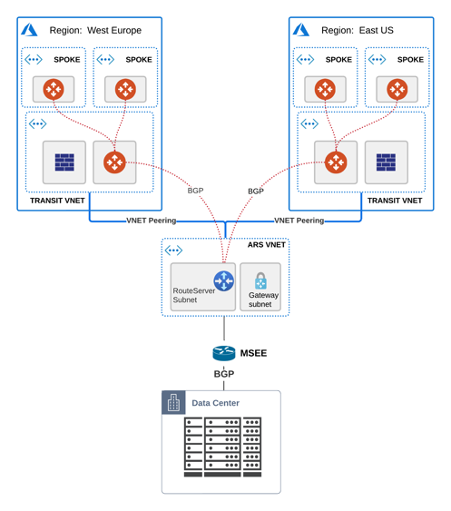
The BGP sessions of one of the Aviatrix Transit NVAs to the two legs of the Azure Route Server:
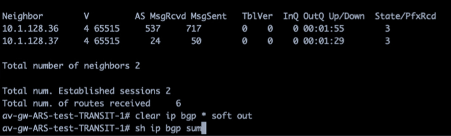
SPOILER:
The Azure Route Server is in fact 2 x VMs which require full mesh BGP connectivity.
If you have only partial, meaning each Avx Transit with just one leg of ARS, then you go into unpredictable/undocumented Microsoft behavior whereas 50% of your traffic can be blackholed => NOT cool
More workloads migrate to the cloud, you assign additional CIDRs to your VNETs and at some point in time when adding a new CIDR you notice an interruption in your OnPremise traffic.
What do you do?
Curious to see what it is you go into your Aviatrix CoPilot, you look at the flow data, you look at gateway resources, latency measurements, you use FlightPath to see if any security group is blocking and ultimately you also check your Firewalls inside the Transit Firenet deployment that no drops are happening there.
Eventually you reach the culprit you least suspect…the BGP sessions from before.
Inside the alert section you see the BGP session has flapped unexplainably as well as webhooks having been sent out from Aviatrix to your ServiceNow or to one of your favorite ChatOps software (Slack, Teams, Webex) warning you about this.
First reaction, scratch your head 🤔, activate more logging and eventually nothing shows up as being murky waters.
You think it was a one time event, close the case and get back to your daily tasks.
Only a few moments later, a Dev adds a new CIDR to one of his VNETs and here we go again.
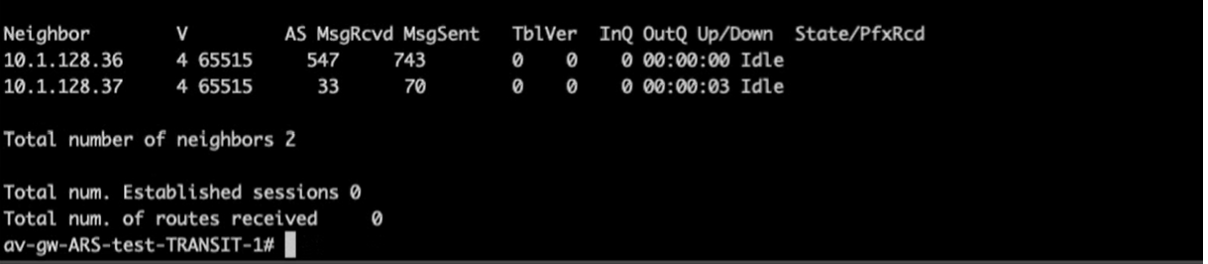
BGP sessions are down and they keep bouncing for a while until they stabilize.
This time around you spot something different:


Not only that but for around 2 minutes the BGP sessions keep coming up and being torn down with the same message, weird right?
You open a Microsoft Support case, it gets assigned somewhere in another geo location and the ping-pong game starts 🏓
You’ve been there before too, right?
You write to the Microsoft Support partner, they relay the information internally to Microsoft themselves, eventually it goes to the Product Group Org, then it bounces back, again the same flow, again reaching you, rewind and time flies.
You invest time, resources, get frustrated and just wish to short-circuit this whole flow but learn this is not possible and that process needs to be followed. Here goes the ball again from left to right and right to left.
A week goes by, another, then a month [ we’re getting there, hang on ]
Eventually you reach someone that can provide you with an answer but by this time your nerves are stretched thin and you’ve gone through all the stages from politely approaching the issue with support to fighting back the workflow and demanding resolution.
And what if the provided answer does not go the extra mile to come up with a workaround but is just the minimal effort required to get you off their head and close the case so that they can move on to the next customer? :)
Does this sound familiar to you?
If yes, you’re probably not the only one to have been here already and as a network engineer at heart you will find the inner workings and the cause quite intriguing.
There is of course a reason for these small outages and BGP session flaps
We all know Cloud does things differently, right?
The Azure Route Server has as per Microsoft documentation, certain constraints among which a limit of 1000 CIDRs advertised to it from the Cloud side.
A bit of searching reveals this:

You might be thinking now:
wait a bit, when we add a new CIDR, this sends a BGP Route Refresh and any traditional network vendor, Cisco, Juniper, Linux with FRR/exaBGP/BIRD/goBGP would NOT double-count the already existing CIDRs in the RIB.
The approach I had when I went through this
First of all, never give up on your support ticket, it will eventually reach the right person that knows how the implementation has been done and that will provide the required info.
Just continue to apply the proper pressure to drive resolution and exit the back-and-forth motion.
Second and I know it’s painful, try to lookup every bit and byte of documentation you can find (and no, in this case none of your AI friends knew the answer).
Extensive searching and eventually also a support update revealed this article:
https://learn.microsoft.com/en-us/azure/route-server/route-server-faq
where one of the comments stated:
Currently, Route Server can accept a maximum of 1000 routes from a single BGP peer. When processing BGP route updates, this limit is calculated as the number of current routes learnt from a BGP peer plus the number of routes coming in the BGP route update.
For example, if an NVA initially advertises 501 routes to Route Server and later re-advertises these 501 routes in a BGP route update, the route server calculates this as 1002 routes and tear down the BGP session.
and an even better one to complement it:
When a VNet peering is created between my hub VNet and spoke VNet, does this cause a BGP soft reset between Azure Route Server and its peered NVAs?
Yes.
If a VNet peering is created between your hub VNet and spoke VNet, Azure Route Server will perform a BGP soft reset by sending route refresh requests to all its peered NVAs. If the NVAs do not support BGP route refresh, then Azure Route Server will perform a BGP hard reset with the peered NVAs, which may cause connectivity disruption for traffic traversing the NVAs.
Is this standard? => Probably not.
Is this to be expected?
I’d say not a big surprise. Most cloud providers have their very own understanding of network concepts and often the underlying SDN implementation is not really following what we learned while going through RFCs, CCNP/CCIE courses or hands-on datacenter setups. This is a world of its own.
First reaction
You ask support, can we do anything about it?
The obvious answer comes: “do route summarization so that 2 x your CIDRs are still under 1000”.
Word of wisdom, it seems that this double counting information is cached somewhere and once a certain amount of time passes (1-2 minutes after a BGP Route Refresh) the counter is accurate again with 1 x the number of received CIDRs.
This allows you to do Route Refreshes at different time intervals without experiencing outages as long as the number of adv cidrs x 2 < 1000 / neighbor to be refreshed.
What if your ranges are a bit stretched all over the place and you cannot aggregate them per Transit island?
There are 3 solutions to this:
- add another Transit as additional layer of aggregation and as the only “gate” toward ARS (sandwich approach)
- ask Microsoft to increase the limitation
- extend your overlay network from the Aviatrix Transit to an Aviatrix Edge device OnPremise (HW or virtual) and no longer require any ARS (effectively removing the root cause of the issue)
Solution 1 - Add another Transit Layer for CIDR aggregation
You connect your Transit areas to a new Transit and that one faces now the Azure Route Server.
Direction new Transit toward Azure Route Server you aggregate all your VNET CIDRs into some less specific CIDR (maybe some /15, /16, depends on how your address plan is).
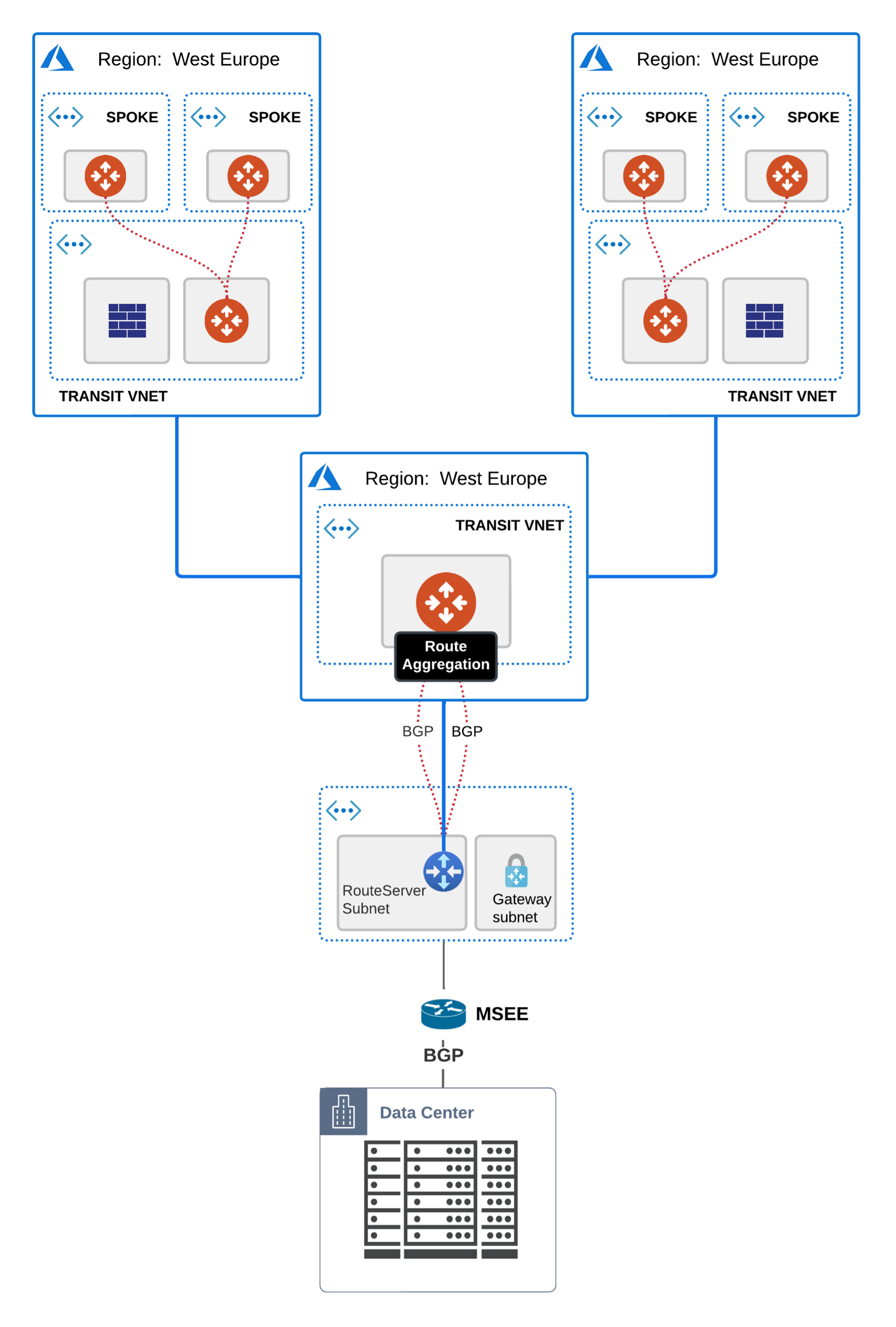
Solution 2 - Ask Microsoft to increase the CIDR limit
Yes, you heard me right.
Even if not offered by default as a mitigation choice, it is possible.
Try to ask for it to be raised to 2000 or 4000 CIDRs.
This at least gives you a breathing space.
Also, please don’t use this as permanent fix.
While it does work out, non-standard setups either on customer or vendor side always have the risk of coming back to haunt you in the future (maybe the CSP does an infra change and this limit resets in the future to the default value, maybe you continue assigning IP CIDRs that are not easy to aggregate knowing the safety net is further away and then forgetting about it you hit the limit again in the future, the reasons can be many).
Solution 3 - Remove ARS and add an Aviatrix Edge device in the Datacenter
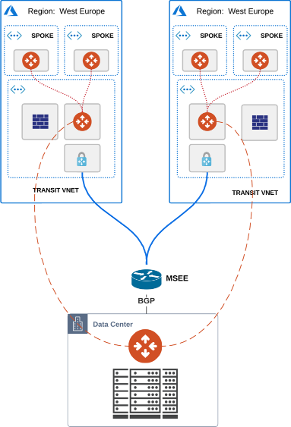
This extends your Aviatrix Environment from Cloud to OnPremise providing the same architecture, same connectivity model and same observability and monitoring, day2ops tooling across the whole spectrum.
To put it bluntly, it keeps your life simple and wins you back some time :)
You get the same SDN Controller deploying your connectivity and security policies end to end.
How did the Support case turn out
Before coming to a closure, you might be wondering how the support case turned out.
It took approximately 1 month of back and forth communication which culminated with the conclusion that the limit is documented in the FAQ, that this behavior has always been so and that spoiler, classic reply following the product team is investigating ways to improve this in the future.
It works as designed
I hope this post has been useful to those of you which hit similar issues in the past and if in doubt or if you have any similar experiences you’d want to share, then feel free to hit me up. $$ I always enjoy a good talk, brainstorming and a challenge.